

ㅤ
ㅤ
Integrate AI CLI with Obsidian knowledgebase
robust CLI with RAG capabilities
AIChat is a comprehensive, all-in-one command-line interface (CLI) tool designed to facilitate efficient interaction with large language models (LLMs) and streamline AI-driven workflows across multiple platforms and providers.
AIChat supports integration with over 20 leading LLM providers through a single interface, enabling users to switch or compare models seamlessly without needing to manage separate APIs or environments.
AIChat on GitHub: https://github.com/sigoden/aichat
functionalities:
- Session Management: Maintains context-aware conversations allowing for continuity across multiple interactions.
- Roles and Customization: Users can define roles to tailor AI behavior to specific needs, improving response relevance and productivity.
- Macros: Automate repetitive command sequences, enabling complex workflows to be streamlined with minimal manual input.
- Retrieval-Augmented Generation (RAG): Integrates external documents to provide richer and more contextually accurate responses.
- Function Calling: Connects language models to external tools and data sources, expanding AIChat’s capabilities beyond text generation.
Model selection
CLI automatically fetches available models - (you have to configure config.yaml by providing API keys for each provider you want to use with aichat)
❯ aichat --list-models
openai:gpt-5
openai:gpt-5-chat-latest
openai:gpt-5-mini
openai:gpt-5-nano
openai:gpt-5-codex
openai:gpt-4.1
openai:gpt-4.1-mini
openai:gpt-4.1-nano
openai:gpt-4o
openai:gpt-4o-mini
openai:o4-mini
openai:o4-mini-high
openai:o3
openai:o3-high
openai:o3-mini
openai:o3-mini-high
openai:gpt-4-turbo
openai:gpt-3.5-turbo
claude:claude-sonnet-4-5-20250929
claude:claude-sonnet-4-5-20250929:thinking
claude:claude-opus-4-1-20250805
claude:claude-opus-4-1-20250805:thinking
claude:claude-opus-4-20250514
claude:claude-opus-4-20250514:thinking
claude:claude-sonnet-4-20250514
claude:claude-sonnet-4-20250514:thinking
claude:claude-3-7-sonnet-20250219
claude:claude-3-7-sonnet-20250219:thinking
claude:claude-3-5-haiku-20241022
gemini:gemini-2.5-flash
gemini:gemini-2.5-pro
gemini:gemini-2.5-flash-lite
gemini:gemini-2.0-flash
gemini:gemini-2.0-flash-lite
gemini:gemma-3-27b-it
AIChat’s Approach to RAG
The AIChat tool integrates RAG capabilities natively through the following mechanisms:
Built-in Vector Database and Full-Text Search Engine: AIChat does not require external third-party services for search and retrieval. It uses an internal vector database to store embeddings of documents and a full-text search engine that enables efficient and scalable retrieval of relevant information based on user queries.
Multi-Source Knowledge Base Construction: AIChat allows building RAG knowledge bases from various document sources. These include:
- Local files stored on a user’s machine or server.
- URLs from which documents can be crawled recursively.
- Any custom document loaders designed to handle specific file types or data sources.
Custom Document Loaders: To enhance flexibility, users can configure custom loaders to process a variety of document formats, such as PDFs or DOCXs. This often involves integrating external tools like
pdftotextfor PDF extraction orpandocfor document conversions.
In this demonstration, I will use AIChat with text-based files in Markdown format (.md).
User configuration
file embeddings are not stored in vector database, instead aichat dumps all the vectors to local yaml file
To show RAGs, sessions, user config, default model, and many other parameters, simply run:
❯ aichat --info
model gemini:gemini-2.5-flash
temperature null
top_p null
use_tools null
max_output_tokens null
save_session null
compress_threshold 4000
rag_reranker_model null
rag_top_k 5
dry_run false
function_calling true
stream true
save false
keybindings emacs
wrap no
wrap_code false
highlight true
theme dark
config_file C:\Users\<USERNAME>\AppData\Roaming\aichat\config.yaml
env_file C:\Users\<USERNAME>\AppData\Roaming\aichat\.env
roles_dir C:\Users\<USERNAME>\AppData\Roaming\aichat\roles
sessions_dir C:\Users\<USERNAME>\AppData\Roaming\aichat\sessions
rags_dir C:\Users\<USERNAME>\AppData\Roaming\aichat\rags
macros_dir C:\Users\<USERNAME>\AppData\Roaming\aichat\macros
functions_dir C:\Users\<USERNAME>\AppData\Roaming\aichat\functions
messages_file C:\Users\<USERNAME>\AppData\Roaming\aichat\messages.md
Generate embeddings from Obsidian docs
I’m going embed all documents from one of my obsidian vaults I use to write/save articles about certain technology + some minor “how to” articles
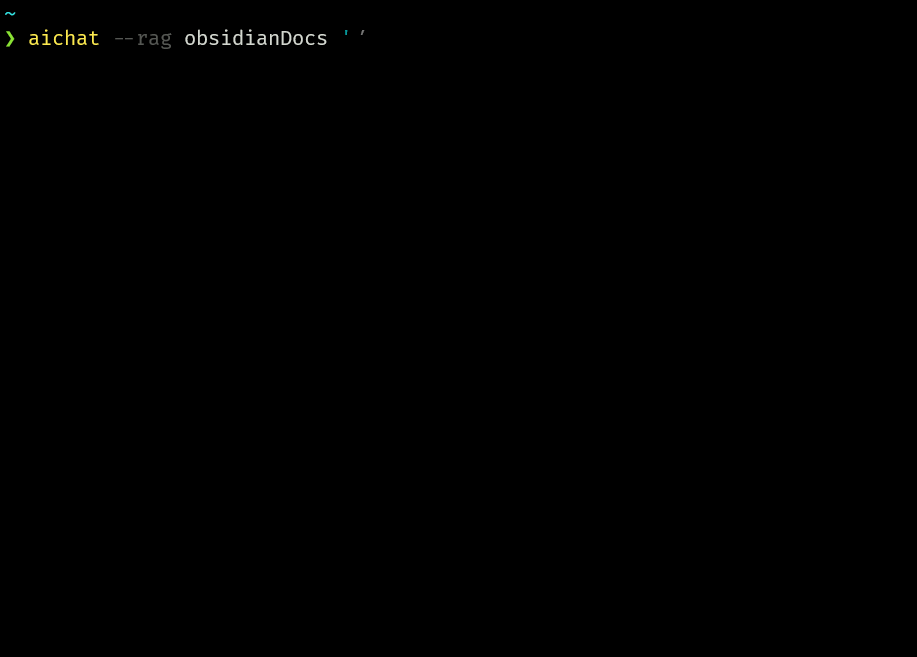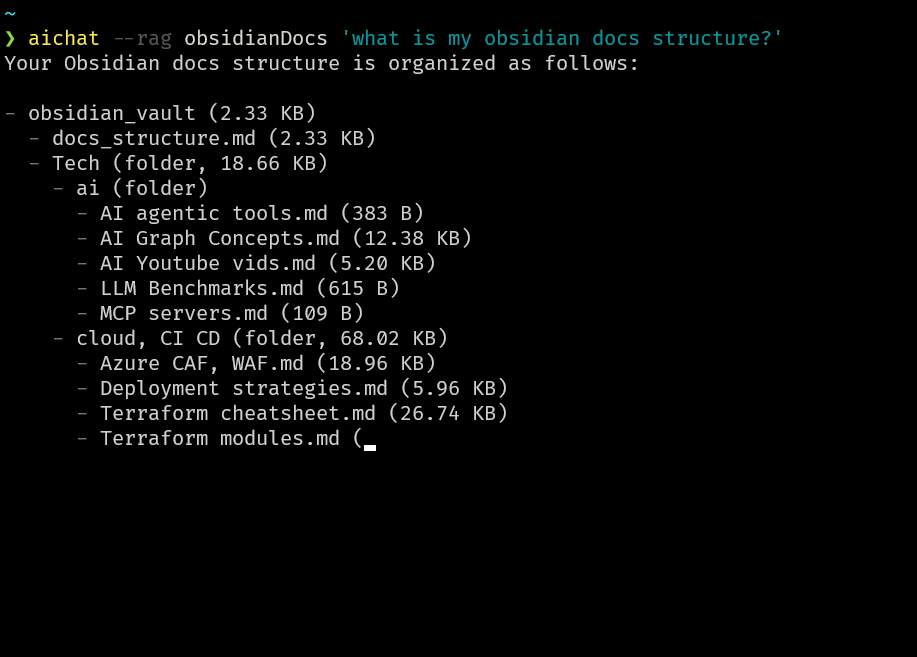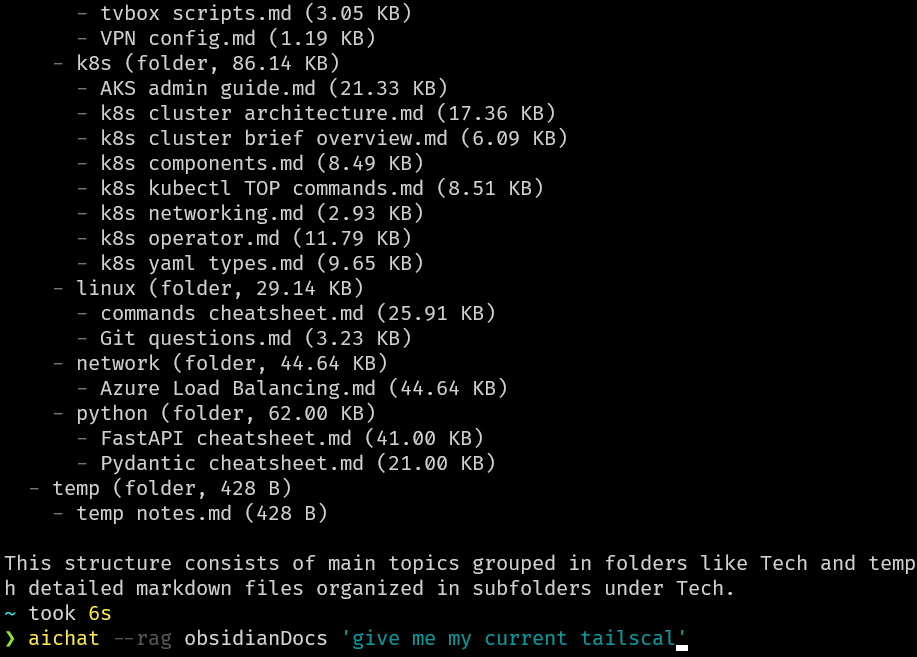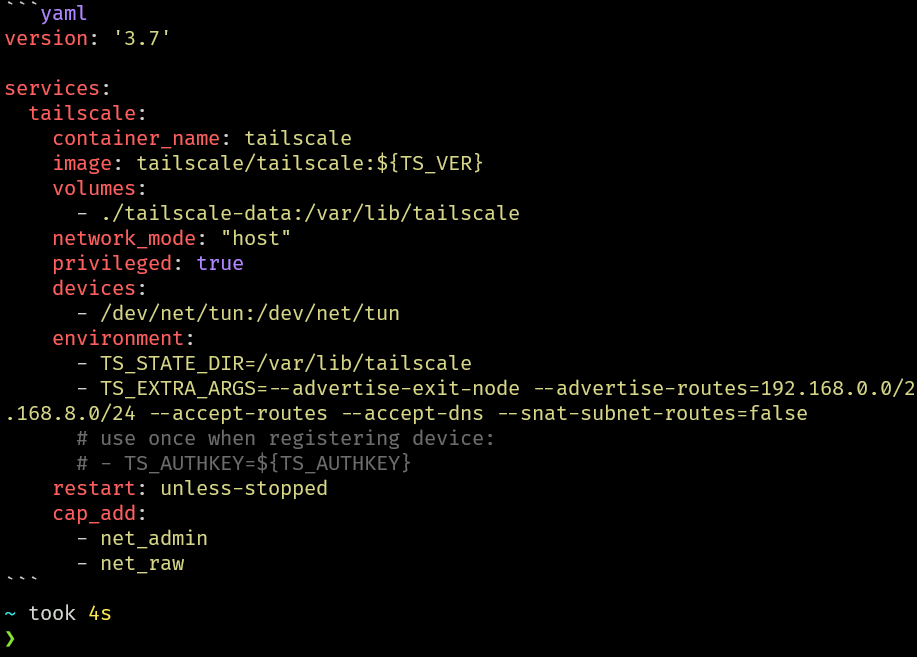
Obsidian docs structure:
Mode Length Hierarchy
---- ------ ---------
l---- 2,33 KB obsidian_vault
-a--- 2,33 KB ├── docs_structure.md
lar-- 0,00 B ├── Tech
lar-- 18,66 KB │ ├── ai
la--- 383,00 B │ │ ├── AI agentic tools.md
la--- 12,38 KB │ │ ├── AI Graph Concepts.md
la--- 5,20 KB │ │ ├── AI Youtube vids.md
la--- 615,00 B │ │ ├── LLM Benchmarks.md
la--- 109,00 B │ │ └── MCP servers.md
l---- 68,02 KB │ ├── cloud, CI CD
la--- 18,96 KB │ │ ├── Azure CAF, WAF.md
la--- 5,96 KB │ │ ├── Deployment strategies.md
la--- 26,74 KB │ │ ├── Terraform cheatsheet.md
la--- 16,37 KB │ │ └── Terraform modules.md
lar-- 4,92 KB │ ├── db
la--- 4,92 KB │ │ └── Database migrations.md
lar-- 4,90 KB │ ├── homelab
la--- 681,00 B │ │ ├── Benchmarks.md
la--- 3,05 KB │ │ ├── tvbox scripts.md
-a--- 1,19 KB │ │ └── VPN config.md
l---- 86,14 KB │ ├── k8s
la--- 21,33 KB │ │ ├── AKS admin guide.md
la--- 17,36 KB │ │ ├── k8s cluster architecture.md
la--- 6,09 KB │ │ ├── k8s cluster brief overview.md
la--- 8,49 KB │ │ ├── k8s components.md
la--- 8,51 KB │ │ ├── k8s kubectl TOP commands.md
la--- 2,93 KB │ │ ├── k8s networking.md
la--- 11,79 KB │ │ ├── k8s operator.md
la--- 9,65 KB │ │ └── k8s yaml types.md
lar-- 29,14 KB │ ├── linux
la--- 25,91 KB │ │ ├── commands cheatsheet.md
la--- 3,23 KB │ │ └── Git questions.md
lar-- 44,64 KB │ ├── network
la--- 44,64 KB │ │ └── Azure Load Balancing.md
l---- 62,00 KB │ └── python
la--- 41,00 KB │ ├── FastAPI cheatsheet.md
la--- 21,00 KB │ └── Pydantic cheatsheet.md
l---- 428,00 B └── temp
la--- 428,00 B └── temp notes.md
Embedding Models
usually I run OpenAI’s text-embedding-3-small / text-embedding-3-large specialized embedding models, they are designed for high-quality text embeddings and widely used for semantic search, clustering, and similarity. These models work well with any textual data, including documentation
Document Splitting (Chunking)
Documents must be split into smaller chunks before generating embeddings. This splitting helps retrieval systems find more precise and relevant passages instead of retrieving entire large documents that may include irrelevant sections.
Chunk Size
- Definition: The number of tokens (or words) included in each chunk (passage).
- If chunks are too large, embeddings average many different topics or ideas, leading to vague or less focused retrieval. This reduces precision because the embedding vector represents a mixture of concepts.
- If chunks are too small, embeddings may lose enough context for meaningful semantic representation, or retrieval becomes noisy because the model treats meaningful phrases as separate chunks.
Chunk Overlap (Chunk Stride / Chunk Overlay)
- Definition: The amount of text (number of tokens) that overlaps between consecutive chunks. For example, if chunk size is 200 tokens and chunk overlap is 50 tokens, then chunks 1 and 2 share 50 tokens at the boundary.
- Overlapping chunks ensure that important information that lies at the boundary of chunks is not lost or split unnaturally. This maintains context across chunks and makes retrieval more robust.
- It smooths the segmentation artifacts when retrieving passages — relevant information at chunk edges is not missed.
- Typical values: About 10-30% of chunk size (e.g., 20-50 tokens overlap for 200 token chunks).
Here is an example how to store documents as embeddings:

Retrieval
Now let’s test our embedded Obsidian documents. There are many factors crucial for producing accurate and relevant outputs, including:
- Removing noise, irrelevant content, and duplicates.
- Normalizing text (e.g., consistent casing, removing special characters).
- Segmenting large documents into meaningful chunks to improve retrieval granularity.
- Storing relevant metadata (e.g., source, timestamps, categories) to improve filtering and reranking
- Choosing an appropriate embedding model that captures semantic meaning well for your domain.
- Consistent embedding parameters (e.g., dimension size, normalization) for all documents.
- Configuring chunk lengths that balance context completeness with embedding specificity.
- Too large chunks can dilute semantic focus
- Too small chunks may lose context or cause excessive noise
Let’s try:
Summary
Well that’s all I wanted to share with you guys,
Integrating AIChat with your Obsidian knowledge base via CLI and RAG techniques provides a powerful, flexible, and efficient way to leverage your personal or professional documents.
By combining my Obsidian documents with AIChat’s built-in vector search, I’m able to retrieve relevant information quickly and enrich AI interactions with precise, context-aware responses. This setup has streamlined how I leverage LLMs alongside my personal knowledge, improving both productivity and output relevance.
Check out second part: Obsidian + Codex CLI and MCP server

